Criando uma função em R para obter dados de inflação, núcleos de inflação e índice de difusão
Nessa publicação será apresentado ao leitor alguns conceitos macroeconômicos sobre inflação, núcleos de inflação e índice de difusão. Posteriormente, serão apresentadas formas de obter dados sobre esses conceitos diretamente pelo R, onde serão criadas funções contemplando a coleta e tratamento dos mesmos, facilitando a vida daqueles que procuram ter uma recorrência na sua obtenção.
Introdução
O que é inflação? Pela definição do IBGE, inflação é como se denomina o aumento dos preços de produtos e serviços. Já nas aulas de economia, aprende-se que inflação é o nome dado para o aumento generalizado e persistente dos preços de produtos e serviços. A princípio não parece haver muita diferença, não é mesmo? Entretanto há, e com isso, exploraremos esses pontos ao longo dessa publicaçã.
Por outro lado, uma taxa de inflação mede a magnitude ao qual os preços de determinada cesta de bens e serviços variam de um período para outro. Para o caso brasileiro, existem diversos índices de inflação, que acompanham diferentes itens, com diferentes proporções, como o IPC, o INPC, o IGP-M, o IPCA – sendo que na publicação de hoje, focaremos nesse último.
O Índice de Preços ao Consumidor Amplo (IPCA)
O índice de inflação oficial do governo federal do Brasil é o IPCA, utilizado para o Banco Central do Brasil (BCB) cumprir o Regime de Metas de Inflação (RMI), decretado em 1999. Este indicador é calculado e divulgado mensalmente pelo Instituto Brasileiro de Geografia e Estatística (IBGE).
São coletados preços de comércios, prestadores de serviços, concessionárias de serviços públicos e pela internet, estendendo-se do primeiro dia até o último do mês de referência. Além disso, a população-alvo da amostra do IPCA abrange famílias que possuem de 1 até 40 salários mínimos das principais metrópoles brasileiras, sendo elas: Belém, Fortaleza, Recife, Salvador, Belo Horizonte, Vitória, Rio de Janeiro, São Paulo, Curitiba, Porto Alegre, Distrito Federal e municípios de Goiânia, Campo Grande, Rio Branco, São Luís e Aracaju.
A sua cesta de itens é determinada pela Pesquisa de Orçamentos Familiares (POF) – também medida pelo IBGE – que, entre outros pontos, aponta o que a população consome e quanto da renda da família é despendido em cada produto. Dessa maneira, os índices levam em conta também o peso dos itens no orçamento familiar, onde a soma do produtório entre a variação ao mês e o peso dos respectivos itens, nos informa a variação mensal do índice cheio.
Grupos, subgrupos, itens e subitens do IPCA
O IPCA é composto por 9 grupos, os quais são:
- Alimentação e bebidas;
- Habitação;
- Artigos de residência;
- Vestuário;
- Transportes;
- Saúde e cuidados pessoais;
- Despesas pessoais;
- Educação;
- Comunicação.
Sendo que esses 9 grupos são divididos em subgrupos (que por sua vez são divididos em itens e subitens).
Classificações do IPCA
Além da divisão exposta acima, o IPCA também pode ser dividido entre classificações, com suas respectivas mudanças de proporções das últimas duas POF, como na tabela a seguir, extraída e adaptada do BCB:
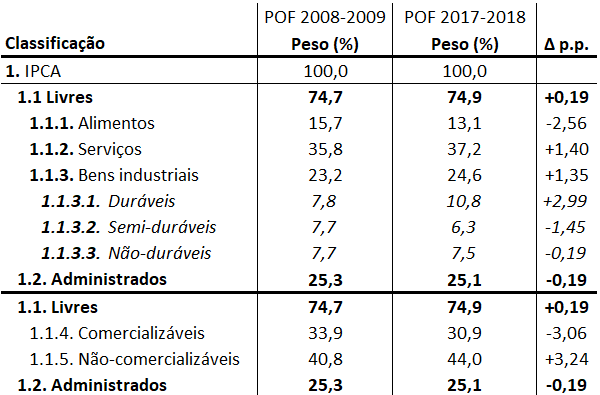
Assim sendo, inseridos no índice, existem preços que são controlados pelo governo (reajustes destes precisam de autorização), os preços administrados; e preços que seguem uma lógica de mercado, isto é, seguem a relação de oferta e demanda, os preços livres. Essas classificações são utilizadas para a elaboração de medidas de núcleos de inflação.
Núcleos de inflação do IPCA
Como alguns itens que compõem o IPCA podem demonstrar variações com menor frequência ou com maior volatilidade, o BCB, buscando a captura e acompanhamento de uma tendência inflacionária com o passar do tempo, baseado em outras economias internacionais, criou medidas auxiliares, os denominados núcleos de inflação.
Nos últimos anos, o BCB calculou, divulgou e considerou em sua comunicação, 7 medidas de núcleos, sendo elas e suas descrições expostas na tabela abaixo:

Entretanto, conforme divulgado no Estudo Especial nº 102 de junho de 2020, o BCB redefiniu o conjunto de núcleos de inflação acompanhados para fins de análise conjuntural. Dessa forma, o novo conjunto proposto é formado por 5 núcleos, sendo que dos núcleos anteriores, foram mantidos 4 (IPCA-EX0, IPCA-EX3, IPCA-MS e IPCA-DP), sendo adicionado o núcleo IPCA-P55, que corresponde à variação do 55-ésimo percentil da distribuição ponderada pelos pesos dos subitens.
São por meio dos núcleos de inflação que conseguimos captar a parte de persistência dos preços de produtos e serviços comentada na seção introdutória.
Índice de Difusão do IPCA
O Índice de Difusão do IPCA é basicamente a relação da quantidade de itens que apresentaram variação positiva entre um período e outro, sobre a quantidade total de itens presentes na cesta, expresso em percentual. Dessa forma, se tivermos um indicador de 60,0% em um mês e no outro ele passa para 58,0%, podemos observar que a quantidade de itens que apresentaram um aumento de preços, se reduziu.
É por meio do Índice de Difusão que conseguimos captar a parte de generalização dos preços de produtos e serviços comentada na seção introdutória.
Mãos na massa! Criando funções no R para extrair inúmeros dados referentes ao IPCA
Após a exploração de alguns conceitos que tangem o IPCA, núcleos de inflação e índice de difusão, passemos para a parte prática, onde iremos extrair informações diversas do SIDRA do IBGE e do SGS do BCB, por meio do R.
Primeiramente, iremos carregar os pacotes que iremos utilizar com a ajuda do pacote pacman (exploro mais sobre esse ponto na publicação Criando uma função em R para calcular a Duration de Macaulay e a Duration Modificada):
#loading packages used
if (!require(pacman)) install.packages(pacman)
pacman::p_load(tidyverse, janitor, sidrar, rbcb)
Dados do SIDRA - IBGE
Criaremos uma variável de data inicial da série, initial_date e lhe atribuíremos um valor arbitrário, e após isso, com o uso da função get_sidra() do pacote sidrar, iremos obter a série histórica do IPCA:
#initial date input
initial_date <- "2011-01-01"
ipca_monthly <- sidrar::get_sidra(
api = "/t/1737/n1/all/v/2266/p/all/d/v2266%2013"
)
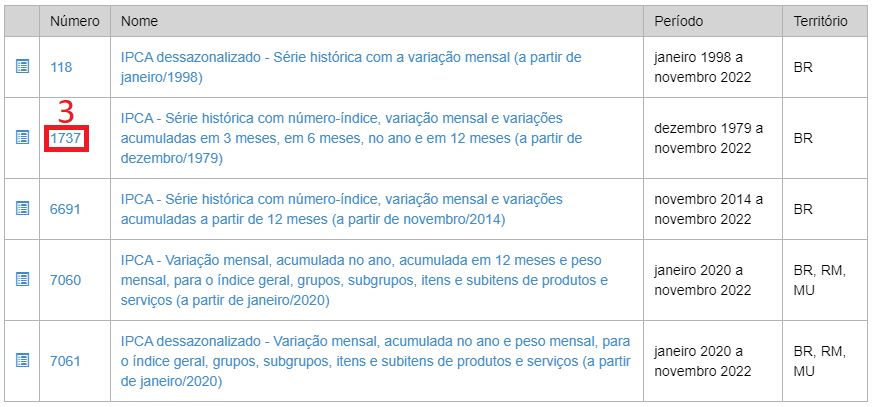
Mas como saber o que colocar no argumento api dessa função? Ao acessar o SIDRA, selecione a coluna do IPCA (1) e depois clique em “Relação de tabelas da pesquisa” (2):

Com isso, abrirá a relação de tabelas respectiva ao IPCA, com o número, nome, período e território da tabela. Nosso interesse é na tabela 1737, sendo possível acessá-la ao clicar em (3):
Feito isso, iremos para a página da tabela 1737. Em variável, selecionar a opção de “IPCA - Número-índice (base: dezembro de 1993 = 100) (Número-índice): < 13 de 13 > casas decimais”; em mês, selecionar “Marcar todos os elementos listados”; e em unidade territorial, a única opção possível é “Brasil”. Ao final da página, logo acima de “Notas”, deverá ser clicado na opção (4):

Assim, será aberta a seguinte página, onde o (5) será o valor que passaremos para o argumento api da nossa função:

Voltando ao R, podemos observar que a tabela que importamos, vem no seguinte formato:
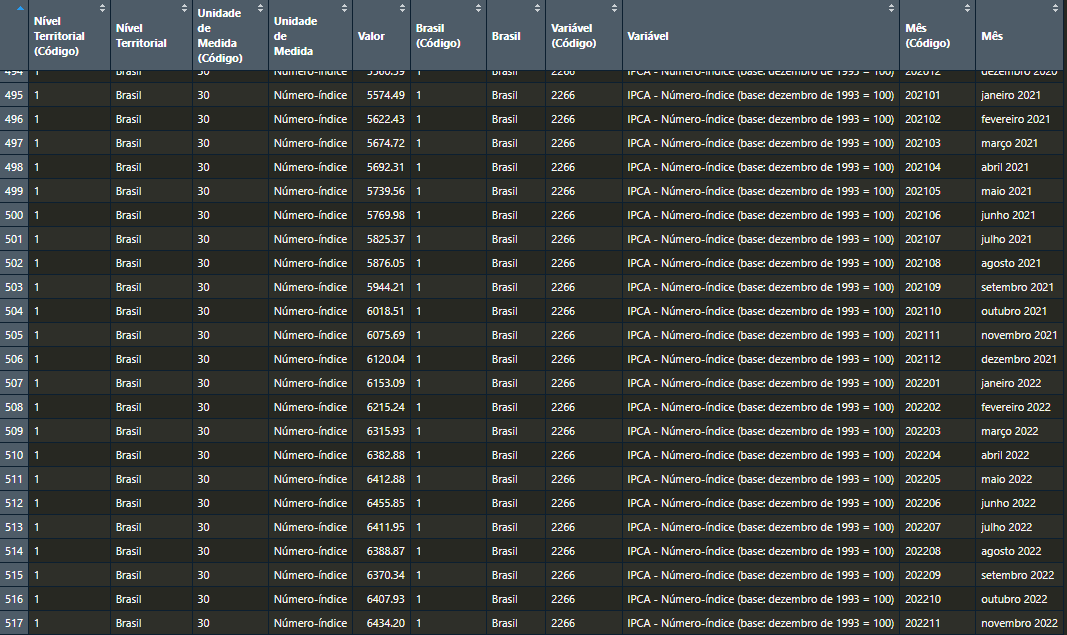
Um tanto quanto “poluída”, não acha? Nomes de colunas em formatação não adequada, muitas colunas desnecessárias para nossa análise e disposição das informações de forma não otimizada para futura manipulação…tratemos esses dados!
Destaque para as colunas Valor, referente ao número-índice do IPCA desde dezembro de 1979; e Mês (Código), referente ao mês e ano, disposto no formato [ano, 4 dígitos][mês, 2 dígitos] (6).
Com o uso do da função mutate(), do pacote dplyr, iremos criar duas colunas:
date, utilizando a funçãoparse_date(), informando como argumentos a coluna de referência e a disposição do formato (6),%Ypara[ano, 4 dígitos]e%mpara[mês, 2 dígitos]; eipca, referente à variação mensal do IPCA (expresso em percentual), que segue o valor arredondado em duas casas (conformeround(expressão, 2)) da seguinte expressão:
#ipca monthly
ipca_monthly <- sidrar::get_sidra(
api = "/t/1737/n1/all/v/2266/p/all/d/v2266%2013"
) |>
dplyr::mutate(
date = readr::parse_date(`Mês (Código)`, "%Y%m"),
ipca = round((Valor/dplyr::lag(Valor, 1) - 1) * 100, 2)
) |>
dplyr::filter(date >= initial_date) |>
dplyr::select(date, ipca)
Criada nossas novas colunas, com a função filter(), selecionamos a data inicial da nossa série, baseada no valor atribuído à variável initial_date; e com a função select(), iremos manter somente as colunas das variáveis que criamos, nos retornando um data.frame com os dados tratados:
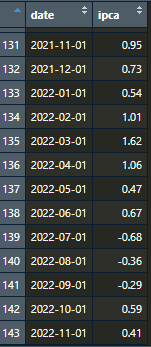
Muito melhor, não é mesmo? Iremos fazer o mesmo processo para captura do ipca15, que a única diferença em relação ao IPCA está apenas no período de coleta, que abrange, em geral, do dia 16 do mês anterior ao dia 15 do mês de referência, funcionando assim como uma prévia do IPCA.
#ipca15 monthly
ipca15_monthly <- sidrar::get_sidra(
api = "/t/3065/n1/all/v/1117/p/all/d/v1117%2013"
) |>
dplyr::mutate(
date = readr::parse_date(`Mês (Código)`, "%Y%m"),
ipca15 = round((Valor/dplyr::lag(Valor, 1) - 1) * 100, 2)
) |>
dplyr::filter(date >= initial_date) |>
dplyr::select(date, ipca15)
Os próximos dados que iremos obter são referentes às variações mensais dos 9 grupos do IPCA. Para obtenção do argumento api, utilizamos o mesmo procedimento explicitado anteriormente, acessando o SIDRA. Além disso, também criaremos a coluna date com a função parse_date(), selecionando ela, a coluna Geral, grupo, subgrupo, item e subitem (renomeada para variable) e a coluna Valor (renomeada para value):
ipca_groups_variation <- sidrar::get_sidra(
api = "/t/7060/n1/all/v/63/p/all/c315/7170,7445,7486,7558,7625,7660,7712,7766,7786/d/v63%202"
) |>
dplyr::mutate(
date = readr::parse_date(`Mês (Código)`, "%Y%m")
) |>
dplyr::select(
date,
variable = "Geral, grupo, subgrupo, item e subitem",
value = Valor
)
Com isso, nos deparamos com o seguinte data.frame:
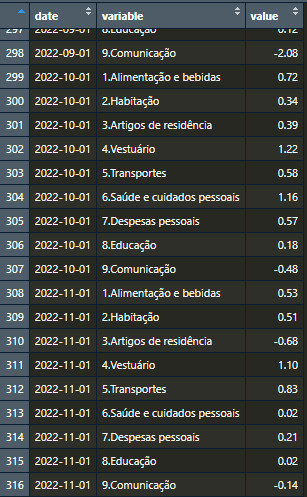
Dessa forma, podemos fazer algumas constatações sobre os dados:
- como puxamos diretamente a variação mensal (e não o número-índice), não precisaremos calculá-la;
- há informação disponível a partir de 01/01/2020 (incluso);
- estão dispostos no formato
long.
Sobre o último ponto, significa que as informações estão representadas de forma mais densa, isto é, são apresentadas com uma coluna contendo todos os valores e outra coluna listando os contextos dos valores, como por exemplo:
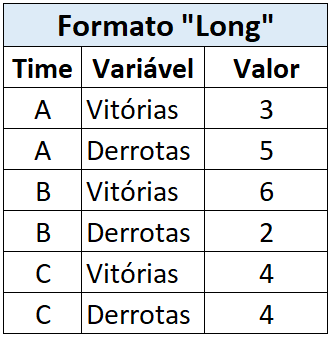
Para nosso caso, será mais interessante deixarmos as informações no formato wide, ou seja, representar cada variável diferente em uma coluna separada:
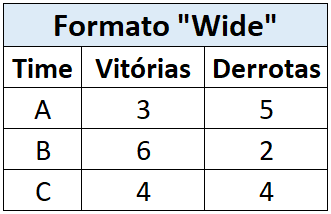
Para isso, utilizaremos a função pivot_wider() do pacote tidyr, onde “pivotaremos” os dados, assim dizendo, transformaremos os valores contidos na coluna variable em novas colunas (argumento names_from = variable), compostos por seus respectivos valores da coluna value (argumento values_from = value):
ipca_groups_variation <- sidrar::get_sidra(
api = "/t/7060/n1/all/v/63/p/all/c315/7170,7445,7486,7558,7625,7660,7712,7766,7786/d/v63%202"
) |>
dplyr::mutate(
date = readr::parse_date(`Mês (Código)`, "%Y%m")
) |>
dplyr::select(
date,
variable = "Geral, grupo, subgrupo, item e subitem",
value = Valor
) |>
tidyr::pivot_wider(
names_from = variable,
values_from = value
)
Fazendo com que a disposição dos nossos dados fique dessa forma:
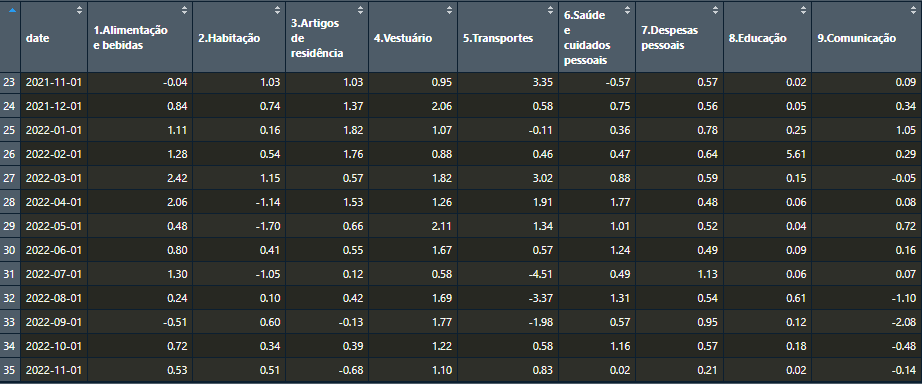
Já melhorou bastante, concorda? Mas ainda falta tratarmos os nomes das colunas, que não estão nem um pouco ideais. Com o uso da função rename_with() do pacote dplyr, iremos aplicar (~) a função gsub(), substituindo os números (pattern = "[[:digit:]]") por nada (replacement = "") de todos os nomes de coluna (x = .):
#ipca groups monthly variation
ipca_groups_variation <- sidrar::get_sidra(
api = "/t/7060/n1/all/v/63/p/all/c315/7170,7445,7486,7558,7625,7660,7712,7766,7786/d/v63%202"
) |>
dplyr::mutate(
date = readr::parse_date(`Mês (Código)`, "%Y%m")
) |>
dplyr::select(
date,
variable = "Geral, grupo, subgrupo, item e subitem",
value = Valor
) |>
tidyr::pivot_wider(
names_from = variable,
values_from = value
) |>
dplyr::rename_with(
~gsub(
x = .,
pattern = "[[:digit:]]",
replacement = ""
)
) |>
janitor::clean_names()
Além disso, com o uso da função clean_names() do pacote janitor, iremos remover pontuações, acentos, espaços e letras maiúsculas, deixando no estilo snake_case:
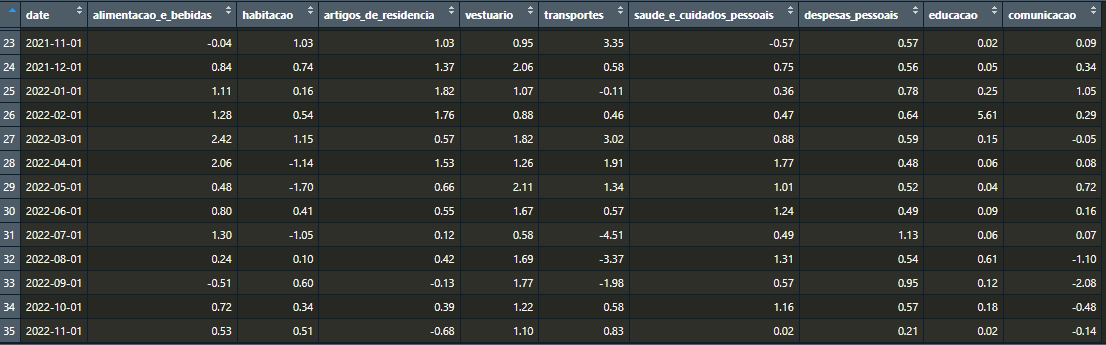
Agora sim, nossos dados estão devidamente tratados. Para obter os pesos mensais de cada grupo, faremos o mesmo procedimento, trocando apenas o valor informado no argumento api.
#ipca groups monthly weight
ipca_groups_weight <- sidrar::get_sidra(
api = "/t/7060/n1/all/v/66/p/all/c315/7170,7445,7486,7558,7625,7660,7712,7766,7786/d/v63%202"
) |>
dplyr::mutate(
date = readr::parse_date(`Mês (Código)`, "%Y%m")
) |>
dplyr::select(
date,
variable = "Geral, grupo, subgrupo, item e subitem",
value = Valor
) |>
tidyr::pivot_wider(
names_from = variable,
values_from = value
) |>
dplyr::rename_with(
~gsub(
x = .,
pattern = "[[:digit:]]",
replacement = ""
)
) |>
janitor::clean_names()
Com esses dois data.frames, podemos calcular a contribuição mensal de cada grupo no IPCA cheio. Bastaria multiplicar o objeto ipca_groups_variation pelo objeto ipca_groups_weight e dividir por 100, entretanto como variáveis do tipo date não podem ser multiplicadas, temos que fazer alguns contornos.
ipca_groups_variation_index <- ipca_groups_variation |>
tibble::column_to_rownames("date")
ipca_groups_weight_index <- ipca_groups_weight |>
tibble::column_to_rownames("date")
#ipca groups monthly contribution
ipca_groups_contribution <- (
ipca_groups_variation_index * ipca_groups_weight_index / 100
) |>
tibble::rownames_to_column() |>
dplyr::rename(
date = rowname
)
Com a função column_to_rownames() e a função rownames_to_column() do pacote tibble, iremos transformar a coluna date de ambos os objetos para o índice do respectivo data.frame, realizar o cálculo e transformar de volta de índice para coluna.
Criando a função auxiliar get_clean_sidra_data()
Dessa maneira, foram abordados todos os dados que iremos puxar do SIDRA. Sendo assim, podemos já consolidar uma função auxiliar, a get_clean_sidra_data(), que usaremos dentro da nossa função final, ao final dessa publicação.
#function to pull clean SIDRA data
get_clean_sidra_data <- function(api, initial_date, rename_to, data_format = "wide") {
if(data_format == "wide") {
get_clean_sidra_data <- sidrar::get_sidra(
api = api
) |>
dplyr::mutate(
date = readr::parse_date(`Mês (Código)`, "%Y%m"),
value = round((Valor/dplyr::lag(Valor, 1) - 1) * 100, 2)
) |>
dplyr::filter(date >= initial_date) |>
dplyr::select(date, value) |>
dplyr::rename(!!rlang::sym(rename_to) := value)
} else {
get_clean_sidra_data <- sidrar::get_sidra(
api = api
) |>
dplyr::mutate(
date = readr::parse_date(`Mês (Código)`, "%Y%m")
) |>
dplyr::select(
date,
variable = "Geral, grupo, subgrupo, item e subitem",
value = Valor
) |>
tidyr::pivot_wider(
names_from = variable,
values_from = value
) |>
dplyr::rename_with(
~gsub(
x = .,
pattern = "[[:digit:]]",
replacement = ""
)
) |>
janitor::clean_names() |>
as.data.frame()
}
return(get_clean_sidra_data)
}
Em que estipulamos 4 argumentos, sendo 2 deles “novos”:
data_format, a princípio se são dados no formatowide(padrão) oulong; erename_to, que é o nome que será dado à coluna (por exemplo, “ipca” ou “ipca15”), referente a renomeação dinâmica, na linhadplyr::rename(!!rlang::sym(rename_to) := value)adicionada.
Por fim, vale comentar que na função get_clean_sidra_data estipulamos uma condição lógica if(condição) {}, em que caso o argumento dado for data_format = "wide", se executará o primeiro procedimento visto (vide o objeto ipca_monthly), e caso contrário (else {}), se executará o outro procedimento (vide o objeto ipca_groups_variation).
Dados do SGS - BCB
Agora que foi mostrado como podemos capturar e tratar dados do SIDRA, iremos falar sobre como puxar dados do SGS - BCB, no qual a princípio, é um procedimento mais simples. Ao acessar o SGS, o usuário se depara com a seguinte interface:
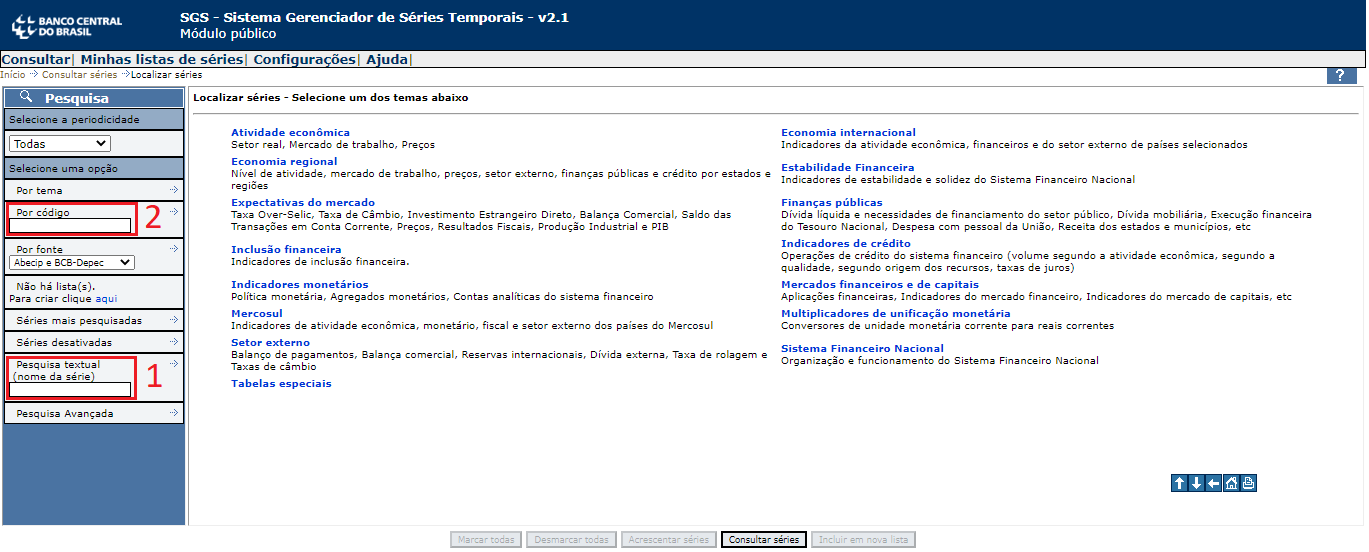
Sendo que em (1), pode-se pesquisar por uma série a partir de uma palavra-chave (como por exemplo, “não comercializáveis” $\rightarrow$ para buscar pela classificação de bens industriais não comercializáveis), ou em (2) pesquisar diretamente pelo código dessa série, caso o leitor previamente já saiba (como por exemplo, “4448”, para o mesmo caso).
Primeiro, criaremos o objeto ipca_classifications_series, contendo as séries das classificações do IPCA:
#ipca classifications series
ipca_classifications_series <- c(
ipca_livres = 11428,
ipca_alimentacao_domicilio = 27864,
ipca_servicos = 10844,
ipca_industriais = 27863,
ipca_duraveis = 10843,
ipca_semi_duraveis = 10842,
ipca_nao_duraveis = 10841,
ipca_administrados = 4449,
ipca_comercializaveis = 4447,
ipca_nao_comercializaveis = 4448
)
Feito isso, com o uso da função get_series() do pacote rbcb, iremos informar nossas séries ao argumento code e a data de início da série ao argumento start_date:
ipca_classifications <- rbcb::get_series(
code = ipca_classifications_series,
start_date = initial_date
)
Neste caso, o objeto ipca_classifications será uma lista contendo os data.frames de cada série, totalizando 10 séries:
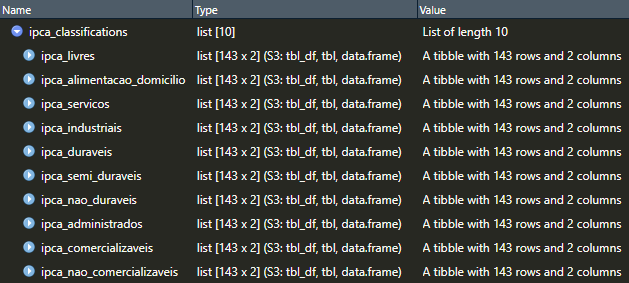
Para deixar todas as séries de classificações do IPCA em um único data.frame, utilizaremos a função reduce do pacote purrr, que irá uni-las com base na coluna date, por meio da função inner_join() (mesma do SQL) do pacote dplyr:
ipca_classifications <- rbcb::get_series(
code = ipca_classifications_series,
start_date = initial_date
) |>
purrr::reduce(
dplyr::inner_join,
by = "date"
)
Dessa maneira, obtemos o seguinte data.frame:
O mesmo procedimento será feito para capturarmos os dados dos núcleos de inflação do IPCA. Primeiramente, iremos criar um objeto com as séries, core_ipca_series, e depois os puxaremos do SGS, salvando no objeto ipca_cores:
#core ipca series
core_ipca_series <- c(
ipca_ex0 = 11427,
#ipca_ex1 = 16121,
#ipca_ex2 = 27838,
ipca_ex3 = 27839,
#ipca_ma = 11426,
ipca_ms = 4466,
ipca_dp = 16122,
ipca_p55 = 28750
)
#ipca cores monthly variation
ipca_cores <- rbcb::get_series(
code = core_ipca_series,
start_date = initial_date
) |>
purrr::reduce(
dplyr::left_join,
by = "date"
)
Entretanto, para este caso, é interessante calcularmos a média por mês dos núcleos de interesse, sendo assim utilizaremos de alguns mecanismos do pacote dplyr:
#ipca cores mean calculation
ipca_cores <- ipca_cores |>
dplyr::rowwise() |>
dplyr::mutate(
ipca_cores_mean = round(
mean(
dplyr::c_across(2:ncol(ipca_cores)),
na.rm = T
),
2)
) |>
as.data.frame()
Com o estabelecimento da função rowwise(), pode-se realizar cálculos de forma “row-at-a-time”, isto é, em conjunto com a função c_across(), conseguimos calcular a média (mean()) de cada linha do data.frame (exceto para a coluna date, que é a 1ª coluna, por isso especificamos da 2ª em diante $\rightarrow$ 2:ncol(ipca_cores)), extraindo o valor arredondado em 2 cadas decimais:
Por fim, resta pegarmos os dados históricos referente ao índice de difusão, que também seguirá o mesmo processo, entretanto sem necessidade de utilizar as funções reduce() e inner_join(), uma vez que se trata apenas de uma série:
#diffusion index serie
diffusion_index_serie <- c(
diffusion_index = 21379
)
#diffusion index monthly
diffusion_index <- rbcb::get_series(
code = diffusion_index_serie,
start_date = initial_date
)
Criando a função auxiliar get_clean_rbcb_data()
Com isso, chegamos ao fim da captura de todos os dados de interesse referentes ao IPCA, logo, podemos criar a nossa segunda função auxiliar, a get_clean_rbcb_data():
#function to pull clean SGS data
get_clean_rbcb_data <- function(series, initial_date) {
if(length(series) == 1) {
get_clean_rbcb_data <- rbcb::get_series(
code = series,
start_date = initial_date
) |>
as.data.frame()
} else {
get_clean_rbcb_data <- rbcb::get_series(
code = series,
start_date = initial_date
) |>
purrr::reduce(
dplyr::inner_join,
by = "date"
) |>
as.data.frame()
}
return(get_clean_rbcb_data)
}
Onde, ela recebe dois argumentos, a(s) série(s) em series e a data inicial em initial_date. Nela é feita uma condição lógica, em que caso o tamanho do objeto dado como argumento para a série seja igual a 1 (if(length(series) == 1) {}), será executado o procedimento conforme visto em diffusion_index, e caso contrário (else {}), como visto em ipca_classifications.
Criando a função final get_ipca_data()
Agora, partimos para a criação da função final, na qual denominaremos ela de get_ipca_data(), que tratará de puxar todos os dados que foram abordados, de uma vez só, tendo como argumento apenas a data inicial, initial_date:
#function to pull all IPCA data
get_ipca_data <- function(initial_date) {
##SIDRA
api_ipca_monthly <- "/t/1737/n1/all/v/2266/p/all/d/v2266%2013"
api_ipca15_monthly <- "/t/3065/n1/all/v/1117/p/all/d/v1117%2013"
api_ipca_groups_variation <- "/t/7060/n1/all/v/63/p/all/c315/7170,7445,7486,7558,7625,7660,7712,7766,7786/d/v63%202"
api_ipca_groups_weight <- "/t/7060/n1/all/v/66/p/all/c315/7170,7445,7486,7558,7625,7660,7712,7766,7786/d/v63%202"
#ipca monthly
ipca_monthly <- get_clean_sidra_data(
api = api_ipca_monthly,
initial_date = initial_date,
rename_to = "ipca"
)
#ipca15 monthly
ipca15_monthly <- get_clean_sidra_data(
api = api_ipca15_monthly,
initial_date = initial_date,
rename_to = "ipca15"
)
#ipca groups monthly variation
ipca_groups_variation <- get_clean_sidra_data(
api = api_ipca_groups_variation,
data_format = "long"
)
#ipca groups monthly weight
ipca_groups_weight <- get_clean_sidra_data(
api = api_ipca_groups_weight,
data_format = "long"
)
#ipca groups monthly contribution
ipca_groups_variation_index <- ipca_groups_variation |>
tibble::column_to_rownames("date")
ipca_groups_weight_index <- ipca_groups_weight |>
tibble::column_to_rownames("date")
ipca_groups_contribution <- (
ipca_groups_variation_index * ipca_groups_weight_index / 100
) |>
tibble::rownames_to_column() |>
dplyr::rename(
date = rowname
)
##SGS
#ipca classifications series
ipca_classifications_series <- c(
ipca_livres = 11428,
ipca_alimentacao_domicilio = 27864,
ipca_servicos = 10844,
ipca_industriais = 27863,
ipca_duraveis = 10843,
ipca_semi_duraveis = 10842,
ipca_nao_duraveis = 10841,
ipca_administrados = 4449,
ipca_comercializaveis = 4447,
ipca_nao_comercializaveis = 4448
)
#core ipca series
core_ipca_series <- c(
ipca_ex0 = 11427,
#ipca_ex1 = 16121,
#ipca_ex2 = 27838,
ipca_ex3 = 27839,
#ipca_ma = 11426,
ipca_ms = 4466,
ipca_dp = 16122,
ipca_p55 = 28750
)
#diffusion index serie
diffusion_index_serie <- c(
diffusion_index = 21379
)
#ipca classifications monthly variation
ipca_classifications <- get_clean_rbcb_data(
series = ipca_classifications_series,
initial_date = initial_date
)
#ipca cores monthly variation
ipca_cores <- get_clean_rbcb_data(
series = core_ipca_series,
initial_date = initial_date
)
#ipca cores mean calculation
ipca_cores <- ipca_cores |>
dplyr::rowwise() |> #rowwise() and c_accross()
dplyr::mutate(
ipca_cores_mean = round(
mean(
dplyr::c_across(2:ncol(ipca_cores)),
na.rm = T
),
2)
) |>
as.data.frame()
#diffusion index monthly
diffusion_index <- get_clean_rbcb_data(
series = diffusion_index_serie,
initial_date = initial_date
)
#creating the complete database
all_inflation_data <- list(
ipca_monthly = ipca_monthly,
ipca15_monthly = ipca15_monthly,
ipca_cores_monthly = ipca_cores,
diffusion_index_monthly = diffusion_index,
ipca_groups_variation_monthly = ipca_groups_variation,
ipca_groups_weight_monthly = ipca_groups_variation,
ipca_groups_contribution_monthly = ipca_groups_contribution,
ipca_classifications_monthly = ipca_classifications
)
return(all_inflation_data)
}
#all data
inflation_data <- get_ipca_data(initial_date = initial_date)
Sendo que ao usá-la, atribuindo-a no objeto inflation_data, temos como output uma lista composta pelos data.frames apresentados:
_output.PNG)
Nos quais podem ser acessados com o operador $, a depender da necessidade, para futura manipulação:
#ipca, ipca15, cores and cores mean
ipca_and_core_monthly <- inflation_data[1:3] |>
purrr::reduce(inner_join)
#diffusion index
diffusion_index <- inflation_data$diffusion_index_monthly
#ipca groups variaton, weight and contribution
ipca_groups_variation <- inflation_data$ipca_groups_variation_monthly
ipca_groups_weight <- inflation_data$ipca_groups_weight_monthly
ipca_groups_contribution <- inflation_data$ipca_groups_contribution_monthly
#ipca classifications
ipca_classifications <- inflation_data$ipca_classifications_monthly
Desse modo, chegamos ao fim dessa publicação, atingindo assim o objetivo de criar uma função que puxe diversos dados (tratados) referentes ao IPCA. Deve-se salientar que os passos efetuados fora dos colchetes de function() {}, foram apenas para fins de didática, explicação e visualização, sendo que os resultados finais a serem considerados são as funções criadas.
Para as próximas publicações, tenho planejado usar os dados coletados aqui para explorar em como criar uma função para calcular rentabilidades (acumuladas desde determinado período, em 12 meses, YTD etc.) de forma agregada, além de também criar gráficos extremamente detalhados, com o auxílio de alguns pacotes, como o ggplot2…até lá!